Databases, Datawarehouses, Datalakes.

All too often I hear terms like "datawarehouses", "datalakes" and even "datalakehouses" in analytics. They are often used interchangeably with no clear picture in my mind of their differences and how they are related. These terms come across very elusive like a black box and just leaves me feeling befuddled.
These terms are all part of the data ecosystem found in many big organisations today. I hope to distill here a clear picture of the differences between a database, datawarehouse and datalake, and how they are related. I will also give brief explanation into what a datalakehouse actually is and hopefully show you that these terms are not as elusive as they first appear.
Databases
Okay let's start with databases. Many of us, without realising, probably already work with a database on a daily basis. Every day examples of a database that one may encounter could be a collection of excel spreadsheets, bank statements, a school register or an accountant's ledger.
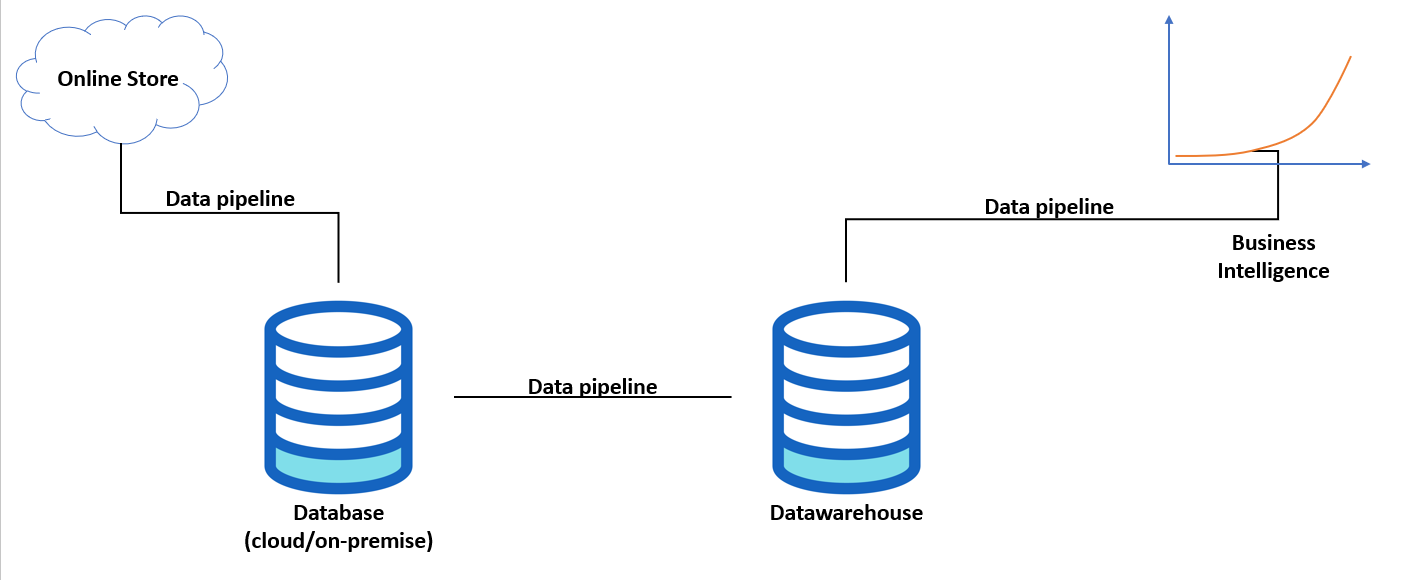
Often when we talk about databases, we are talking about a relational database management systems (RDBMS). These systems are designed for On-Line Transaction Processing (OLTP) or efficiently storing business transactions such as: sales, products, customers in tables with rows and columns.
For example, when a customer orders a product from an online store, the database of that online store creates a new record in an 'Order' table with columns such as: order number, date of order, shipping address, number of items etc. If a customer changes their address details, then the database will update the address details in the 'Customer' table automatically without keeping track of historical data. Hence, these systems are designed to handle thousands of these kind of transactions efficiently but as we will see these have important consequences when it comes to data analytics.
Examples of popular database technologies are: Oracle, MySQL, Microsoft SQL Server, PostgreSQL, MongoDB.
Datawarehouses
Datawarehouses are similar to databases in that they are used to store data but the difference is in it's purpose. To understand the rationale for why it is best practice for organisations to have a datawarehouse, we need to understand the problem of using a database for data analytics.
For example, as a business owner, I want to understand the breakdown of sales year over year and by shipping address for the last 5 years. We can answer this by querying the database of our online store and visualising the data. However, due to the nature of a database, there are two consequences to this:
- Database slows down, affecting the speed of business transactions because you would first need to join sales and date tables together, then filter for the last 5 years and finally aggregate the values in the query, all while in production.
- Unable to answer certain questions because a database does not track historical data such as customer shipping address.
Hence, a different environment, which is separate from the database, although still connected via data pipelines, is needed for data analytics. This is where a datawarehouse come in.
A datawarehouse is an On-Line Analytical Processing (OLAP) system. It is designed to store and analyse large amounts of data. It contains all historical data, which gets updated periodically from the database depending on the data pipeline set up. In contrast to databases where the data is highly detailed in rows and columns, in a datawarehouse the data is highly summarised. Typically, a data analysts uses a buisness intelligence tool on top of a datawarehouse to build reports and generate insights for the business.
The key characteristics of a datawarehouse are:
- Integrated - data from multiple sources are combined together to form a single source of the truth.
- Time Variant - data varies with time.
- Non Volatile (Static) - data does not change, so history is tracked.
- Subject Oriented - answering a particular business question.
Examples of popular datawarehouse technologies are: Snowflake, Azure Synapse Analytics, Amazon Redshift, Google BigQuery, IBM Db2 Warehouse.
Datalakes
A datalake is simply just an environment where all data are stored in its raw format and includes images, videos, json files, database tables etc. In contrast to a datawarehouse where all the data is in a structured format, a data lake store data that is structured, semi-structure or unstructured.
Examples of a datalake are Amazon Web Services, Azure Data Lake, Databricks, Apache Hadoop, Apache Spark. Due to the nature of a datalake to store big data (volume, velocity, variety), a data scientist would typically use the data from a datalake to build machine learning models.
It is tempting to treat a datalake like a data swamp but this creates issues regarding data governance and building a scalable system that can handle different formats of data. This leads to relatively new concept in data analytics called a datalakehouse.
Datalakehouses
Datalakehouse = datawarehouse + datalake
It simply uses the best of both worlds. It's a system which is scalable with big data (volume, velocity, variety) like a datalake, along with the security and structure of a datawarehouse.
This enables all data fields to extract and analyse data froma single place, whether it's for ad-hoc reporting or machine learning.
Summary
Below is a a table that summarises the different properties across databases, datawarehouses and datalakes:
