Data Pipeline Basics


If you work in tech, especially in data, you'll often come across the term 'Data Pipeline'. In this article, I distil what exactly a data pipeline, just enough so that you can be sure to know what your data engineer is talking about next time they mention it.
What is a Data Pipeline?
A data pipeline is best understood as analogous to that of a water pipeline. Water pipelines take water from a source, like a lake or a river, to a central facility for cleaning in order for it to be suitable for human consumption. After this, the cleaned water is taken, again through pipelines, from the central facility to people's homes for drinking.
Data pipelines are very similar. They are software tools that enable data engineers to extract data from a source, like a data lake or a streaming data source, to a staging area for transformation in order for it to be suitable for analytics. After this, the transformed data is taken, again through data pipelines, from the staging area to a data warehouse for analysis.
As you'll notice above, there are a series of steps that follows: extract, transform, load; or, ETL in other words. This is typically what data engineers mean when they are referring to a data pipeline. It is a series of processes that extracts, transforms and loads data from different source systems to a target system. Below is a diagram that visualises this three step process:
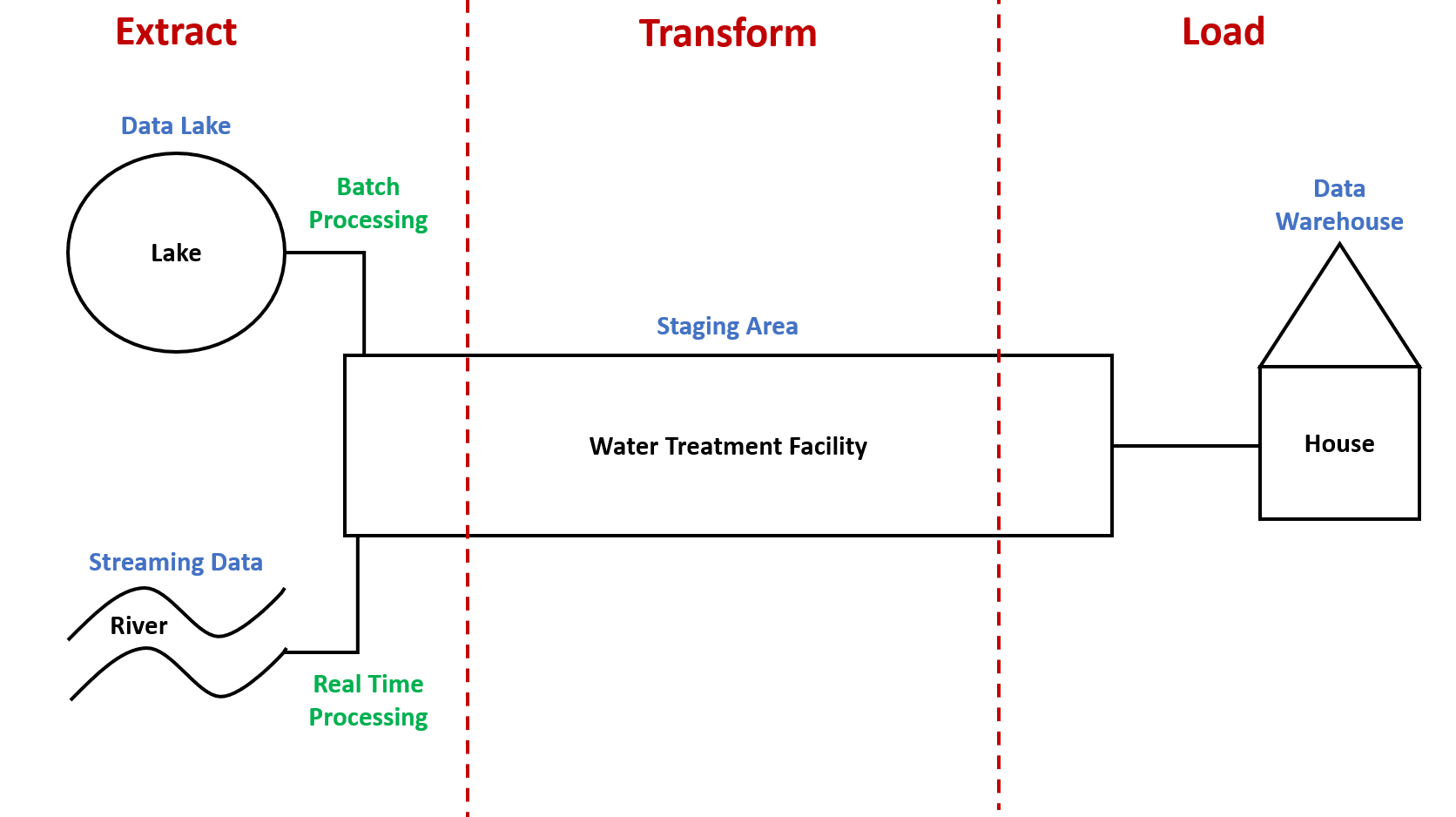
Typically, there are two ways of processing data in a data pipeline:
- Batch Processing is where data, typically in large volumes, are extracted from the source system at regular intervals but not required for quick decision making. Applications of batch processing can be found in billing reporting, revenue reporting etc.
- Real Time Processing is where data are extracted from the source system as it is it is generated in order to make quick decisions. Applications of real time processing can be found in weather forecasting, stock trading etc.
What are common tools for Data Pipelines?
Below is a list of the common tools used by data engineers for developing data pipelines:
- Fivetran
- Apache Kafka
- Apache Spark
- Apache Airflow
- AWS Glue