Introduction to Data Build Tool

Welcome!
Before we begin, I recommend you to read my previous article where I covered data pipelines following the traditional data workflow of Extract, Transform and Load or ETL.
In the modern age, with the advent of technology, compute and storage resources are much cheaper than what they used to be. Hence, you will often come across a data workflow where the Transform and Load steps are reversed, or ELT in other words. The transformation part of this workflow will be the focus of this article.
What is dbt?
DBT is a tool that enables analytics engineers to execute the 'Transform" part of the ELT workflow by writing SQL transformations. Unlike other tools, DBT solved many of the problems developers encountered in a traditional ELT workflow by adopting software best practices such as:
- Modularity
- Reusability
- CI/CD
- Testing
- Documentation
DBT Project Structure
In DBT, the flow of data might look something like the following:
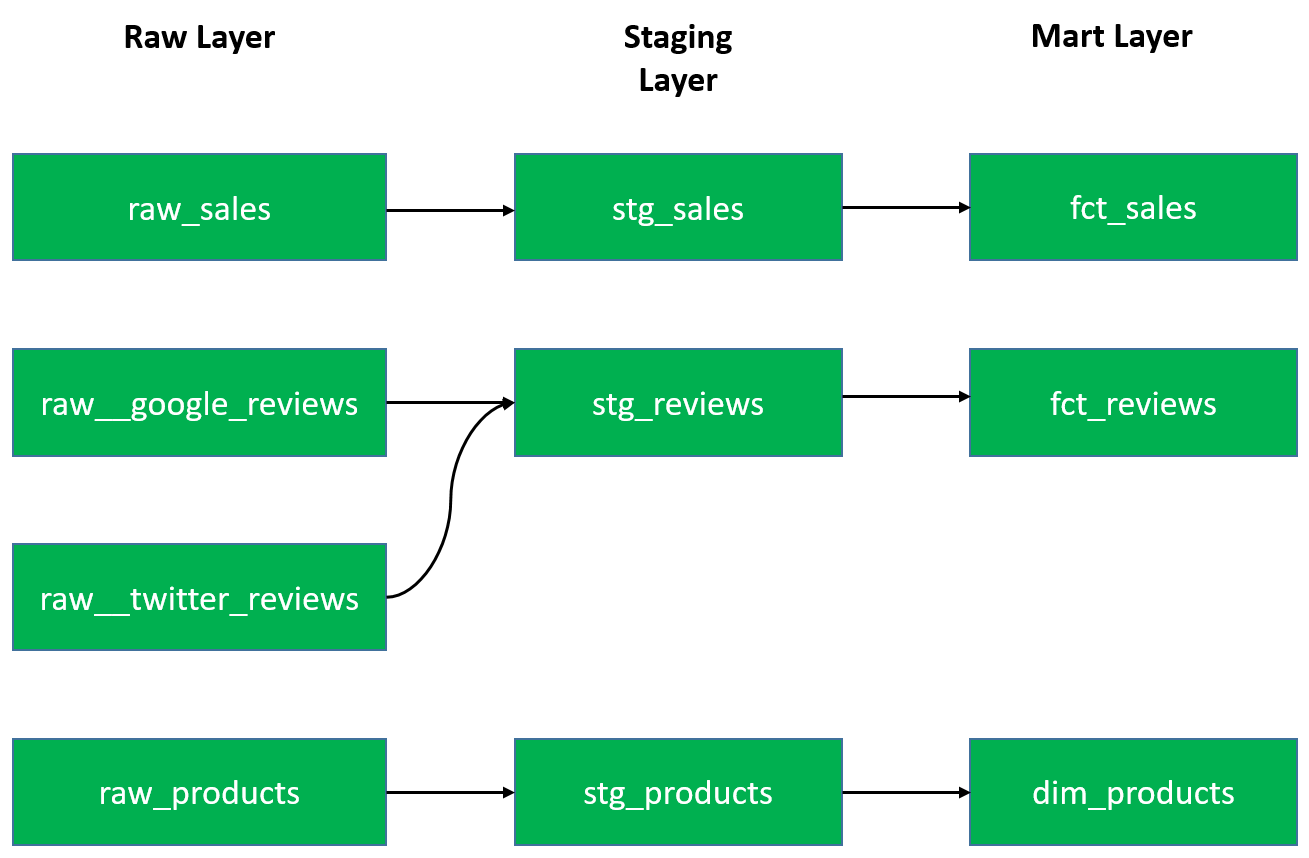
A given table, say raw_sales, undergoes transformation through typically 3 layers as shown above, although there could be multiple intermediate layers if needed. This is a simplified view of a DAG in dbt. DAG stands for Directed Acyclic Graph and it shows the dependencies between the different models in the different layers and how the individual components come together to build the whole. This is one feature of dbt that makes it such a powerful tool when it comes to debugging issues or understanding the impact of upstream changes across the different models.
Below shows an example of a typical dbt project structure:
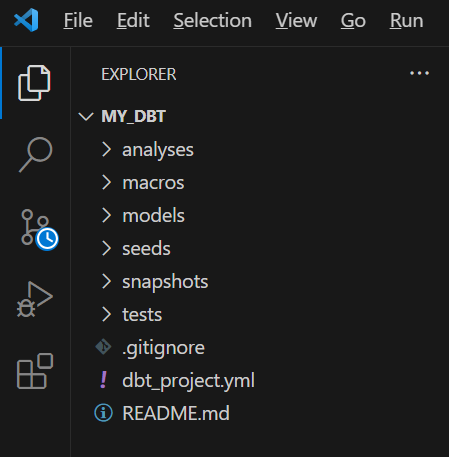
In this dbt project, there are mutiple different folders, each with their own purposes as outlined below:
- Models - These are just .sql files, where data transformations are written in SQL.
- Macros - These are also .sql files that consists of resuable pieces of code, like a function, which can be referenced in multiple models.
- Seeds - These are local files (.csv) stored in datawarehouse, which contain a small amount of data, for example for lookup purposes.
- Snapshots - These are a special type of model in dbt, where changes in the data occur over time. This is useful for when you have slowly changing dimensions, for example, an employees table, where employees change roles over time.
Typically, the model will have a timestamp column called 'last_updated', which tracks the changes.
- Sources - This is a .yaml file, where developers define the location, structure and name of the databases and source (raw) tables.
- Tests - These are .sql files that developers create to test their models and check for any data quality issues.
- Documentation - These are .yaml/.markdown file that dynamically captures information regarding names, defintions and calculations of all tables and fields in your dbt model.
Benefits:
- Open source
- SQL first
- Lineage and impact analysis
- Large community
- Follows software development framework