Power BI - VertiPaq Engine


Power BI is a data visualisation tool and what makes it incredibly efficient from an end users perspective has largely to do with its underlying architecture, specifically the Vertipaq Engine. In this article I will explain what it is, why it is important and how it works.
What is it?
VertiPaq is an in memory, columnar database. It "sits" on top of Power BI. The aim of the VertiPaq Engine is to reduce the memory footprint of a data model through several compression algorithms.
Why is it important?
Two Reasons:
- Reduces the amount of RAM used by a data model.
- Less RAM means faster queries and ultimately a better experience for end users.
Architecture Diagram
The diagram below is a schematic representation of the underlying architecture of Power BI.
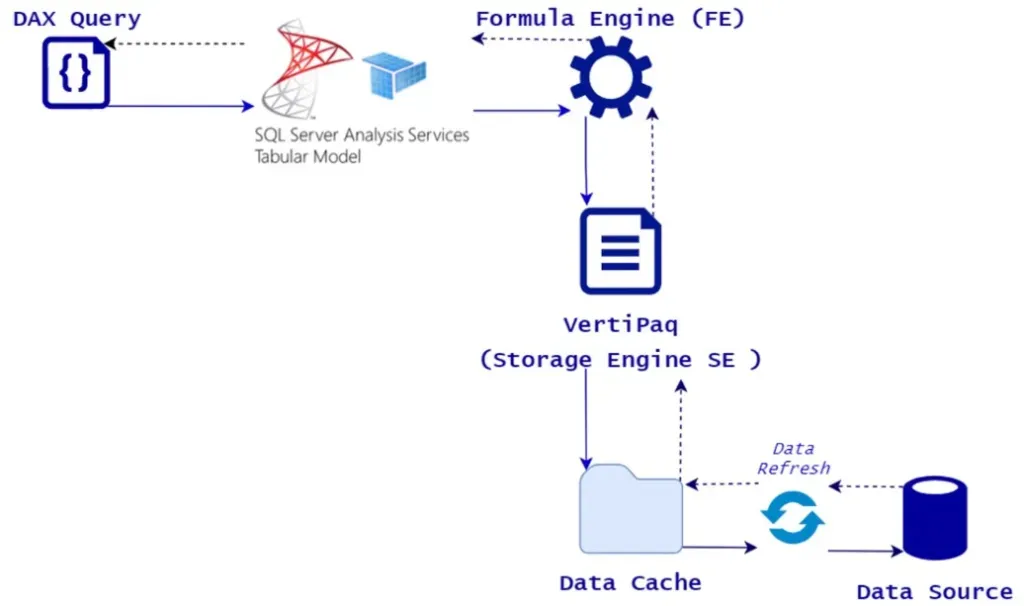
The steps in this diagram are as follows:
- When a visual in Power BI is created, a DAX query is sent to SQL Server Analysis Services Tabular Model (SSAS).
- The role of the Formula Engine is to process the request, generating and executing a query plan.
- The role of the Storage Engine is to read data from data source and store it in data cache data for when Formula Engine requests it. When using import mode for Power BI (most commonly used), the data is stored via VertiPaq implementation of Storage Engine.
How does it work?
The VertiPaq Engine uses 3 types of algorithms to compress the data in memory. To visually see what happens, we will use an example table of exotic fruit orders. This table has 15 rows and 3 columns as shown below.
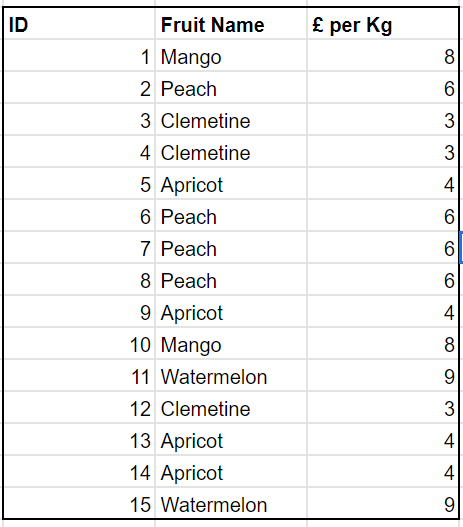
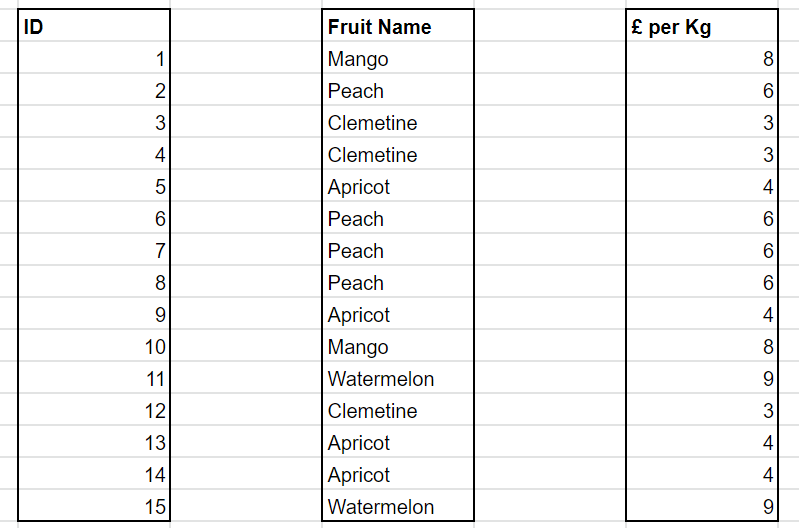
Before getting started, it is important to understand one of the key characteristics of the VertiPaq Engine, which is that it is a columnar database. This means that each column of a table is storedas a separate data structure. In other words, they are physically not adjacent to each other as they would be in a traditional table. Each column (data structure) is treated as an independent object.
Value Encoding
This is the most simplest algorithm to understand. For example, in the column '£ per Kg', which is of data type integer, the engine finds the minimum value of the column and subtracts it from all other values in that column. In this case, the minimum value is 3.
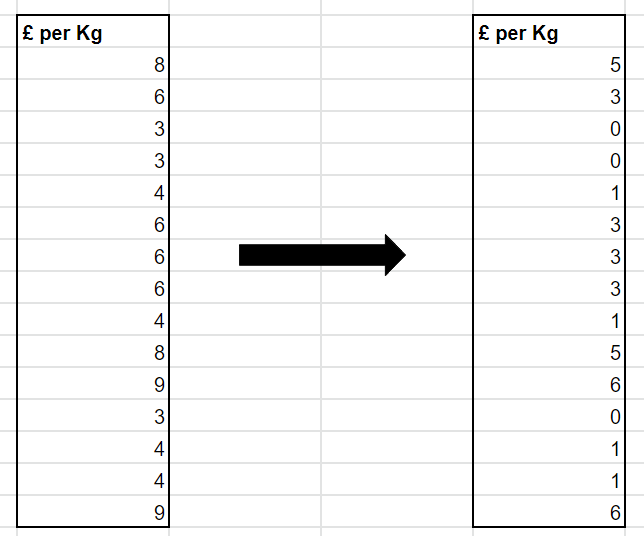
Effectively what the algorithm is trying to do is to reduce the number of digits in a column, which means less bits are required to store the data in memory. The above example only has single digits and 15 rows, which is insignificant at first. However, imagine when you have 6 digit figures and millions of rows, then it would be significant.
Hash Encoding
Obviously Value Encoding only works on columns with data type integer. To deal with other data types, especially strings, this is where Hash Encoding comes in. For example, lets consider the 'Fruit Name' column in our table, which is of string data type.
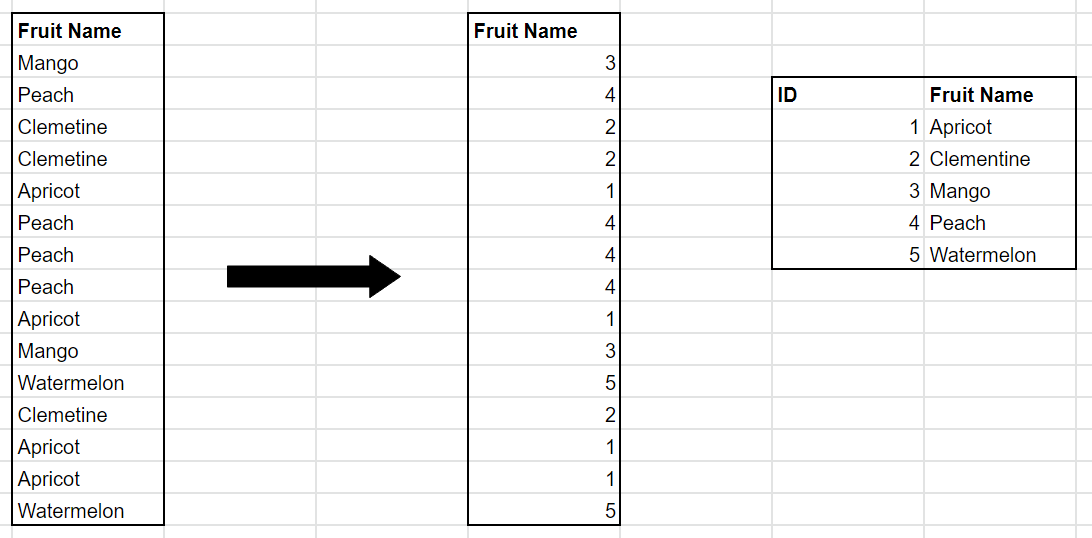
The engine creates a dictionary of all the unique values in the column and assigns a unique integer (i.e. index) to each value. The values in the original column are replaced with their corresponding indexes. Essentially converting a string column into an integer column, which is requires a lot less bits to store in memory, even when you take into account the dictionary size.
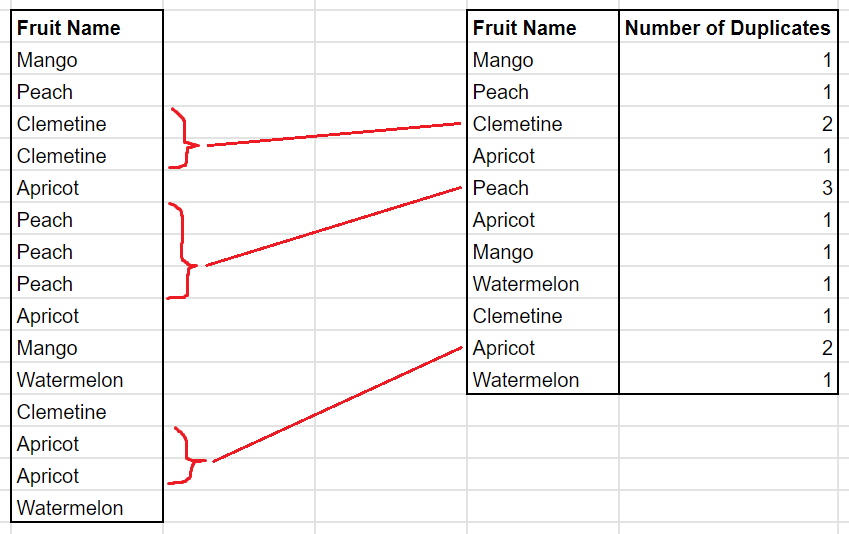
Run Length Encoding
With Run Length Encoding, the engine replaces all adjacent duplicate values in a column with that current value and the number of adjacent duplicates. The figure below shows how this looks.
Run Length Encoding is usually done in conjunction with Hash Encoding. It is similar to the example above but this time the column is already an integer.
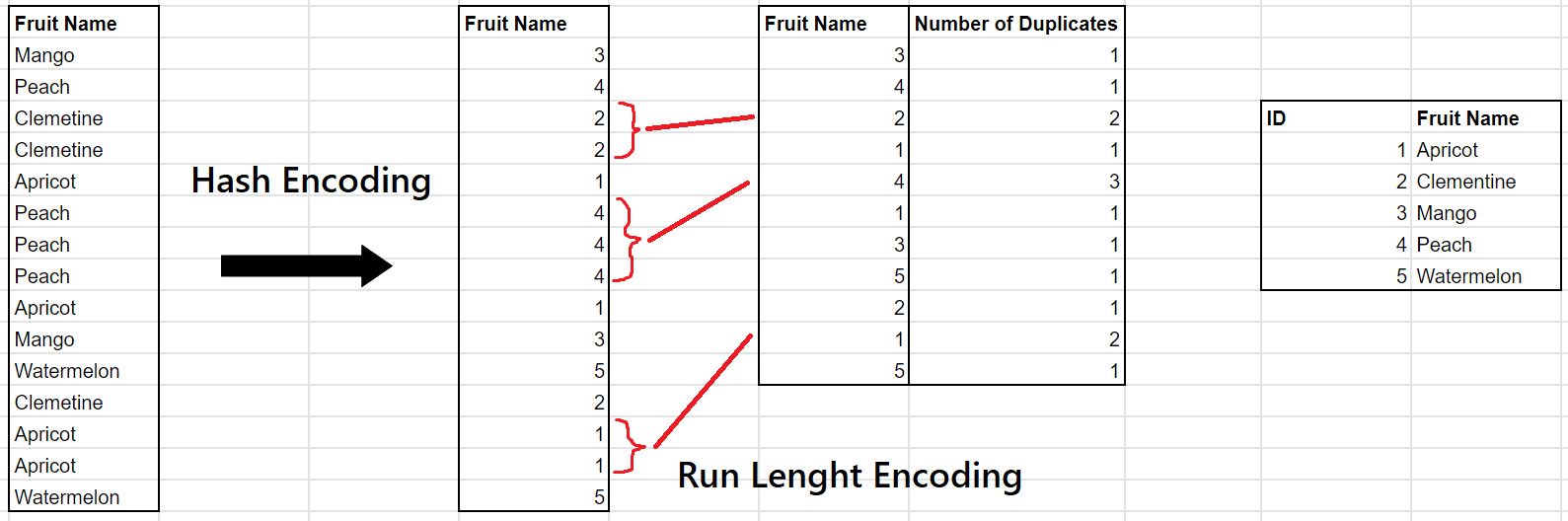
Run Length Encoding is most effective when you have many adjacent duplicate values.
Summary
- VertiPaq is an in memory columnar database.
- It uses several compression algorithms to reduce memory footprint: Value Encoding, Hash Encoding and Run Length Encoding.
- This is what makes Power BI fast.