Titanic Dataset - Key Machine Learning Concepts


The sinking of the Titanic in 1912 was the most disastrous shipwreck of its time. It also makes for a great dataset for machine learning beginners. In other words, the titanic dataset is the "Hello World" of data science and can be found on Kaggle here.
This is my first attempt at applying machine learning algorithms to this dataset and it is such great way to learn many of the basic concepts of machine learning. The purpose of this dataset is to build a model that can accurately predict which passengers onboard the Titanic survived based on certain factors. The aim of this blog is to share 3 key concepts that I have learned during this challenge which are: treating missing values, encoding and feature engineering.
I won't bore you with every line of code, so I will only be showing just those that are relevant. If you want to see the full python script, then you can get it from my GitHub repository here.
First, import required libraries. For data science, it will commonly be Pandas, Numpy and scikit-learn as shown below:
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.preprocessing import LabelEncoderThen, load the training dataset into a dataframe.
df = pd.read_csv('train.csv')Before training a model, it is crucial to explore the training data to identify any columns with missing values or opportunities for feature engineering.
The code below shows a list of all columns of the data:
''' List of columns '''
print(df.columns)Output:

The target variable to predict is called 'Survived'. All other variables, which can be chosen as inputs to the model, are called the 'features' of the model. From this list alone, the features I chose for predicting which passengers survived are 'Plcass', 'Sex' and 'Age'.
Treating Missing Values
Lets explore any missing values in these features:
''' Summary of total null values for all features in dataframe '''
print(df.isnull().sum())Output:
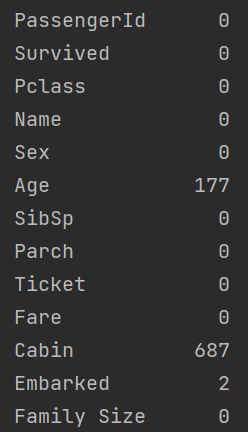
This lead me to the first hurdle. The column 'Age' has null values which are not supported by many machine learning algorithms. Hence, missing values in this column need to be treated before inputting it into the model.
There are many methods of treating missing values. One of which is to just simply delete rows where there are missing values for the Age column. However, the problem with this is that a lot of information will be lost as a result. Instead, a better method is to use imputation of the mean, which is simply replacing all missing values in a column with the mean of all other values of that column. The same can be done for the median or the mode.
#Treating missing values in the 'Age' column using imputation via the mean
df['Age'] = df['Age'].replace(np.NaN, df['Age'].mean())
print(df.isnull().sum())Output:
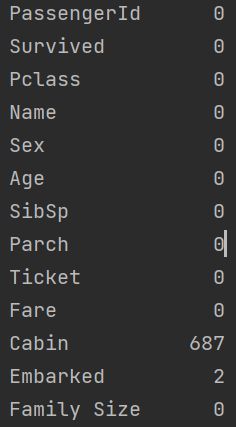
Label Encoding Categorical Variables
Lets explore the datatypes of these features:
''' Columns and their datatypes '''
print(df.dtypes)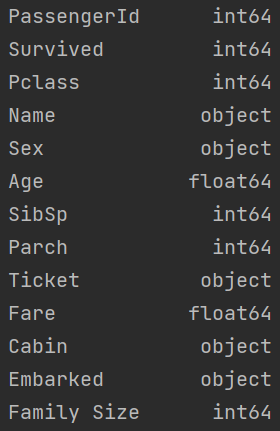
As shown above, the column 'Sex' has a data type of 'object', which in other words mean that it is non numeric. Again, machine learning algorithms can not understand in the same way as humans do what the value of 'Male' or 'Female' mean. However, if we replace the value of 'Male' for the integer 1 and 'Female' for 2, then this is something a computer can understand. This way of mapping non numeric values into numeric is called encoding. There are two main types of encoding: one hot encoding and label encoding.
In this case, I used label encoding as it is the most simplest to understand. All it does is replace all unique values of a categorical variable with a unique numeric value like 1 for 'Male' and 2 for 'Female'. Lets see this in code:
''' create an instance of the class '''
labelencoder = LabelEncoder()
''' List only categorical features that need to be encoding '''
titanic_categorical_features = ['Sex']
''' an efficient way to label encode any number of categorical variables '''
def label_encoding(column):
df[f'{column}_N'] = labelencoder.fit_transform(df[f'{column}'])
return df
''' The code below is to check the resulting dataframe '''
for i in map(label_encoding, titanic_categorical_features):
print(i)Output:
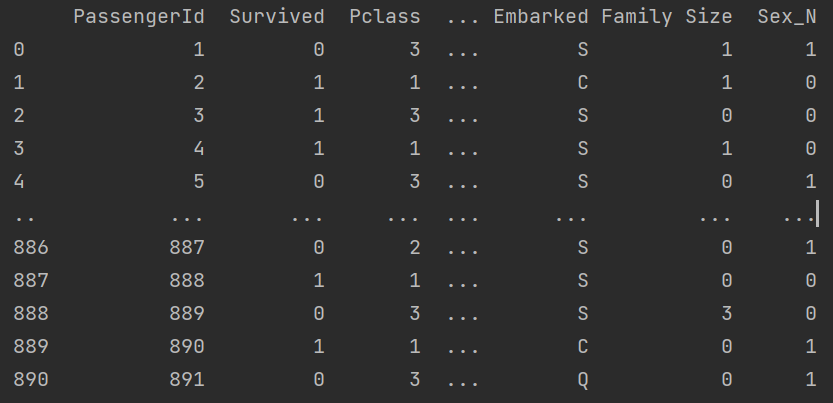
Feature Engineering
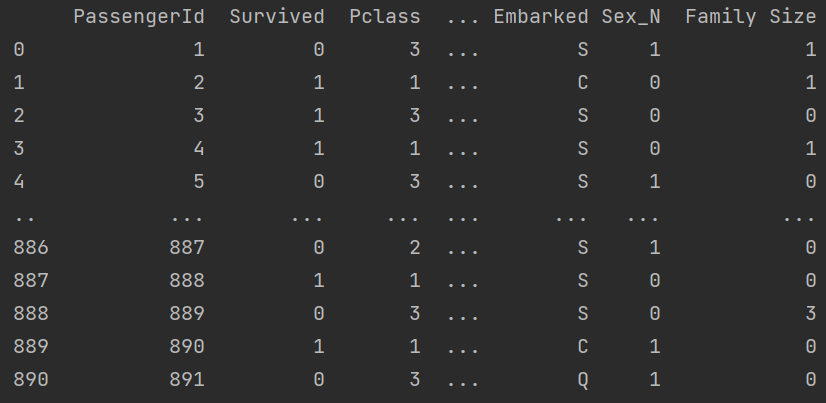
Feature engineering is essentially a way to create more data from your own data. It is very powerful as it can enable you to have more features to model with and discover new patterns. A simple example of this by linear combination (adding) of two numeric columns, 'SibSp' (siblings/spouses) and 'Parch' (parents/children), to give a new column called 'Family Size'.
''' Feature Engineering, e.g. linear combination of features '''
df['Family Size'] = df['SibSp'] + df['Parch']
print(df)Output:
In summary, how to treat missing values, encode categorical variables and do feature engineering are very important for any machine learning problem.
Thanks for reading and don't forget to subscribe for more!